Why On-Call Engineers Ignore Your Runbooks


It's 5:15 AM. An alert fires: payments-api, p99 latency > 2000ms for 5m. Olivia's on call. The team has a runbook, but that’s not where she looks for the solution. She completely ignores it. The last few times she followed one at 5 AM, the fix didn’t match the symptom, or the runbook links attached to the alerts were wrong. So she opens Slack, finds a thread from eight months ago, copies the fix, and goes back to bed.
You wrote that runbook. She didn't use it, and she had reasons. This isn't a failure on Olivia's part. Here's why on-call engineers reach for Slack history before the docs you maintain, and what you can do about it.
The myth of the calm reader
In most cases, documentation is written for a reader who has time. They have the mental bandwidth to read prose, follow a tutorial sequentially, and absorb all the concepts. For an on-call engineer like Olivia, she doesn’t have that time. She’s triaging. She scans, copies and pastes, and bails if it doesn’t work. If your runbook starts with three paragraphs of context before the first command, she’s gone.
The Google SRE book made this point years ago: the quantity of on-call can be calculated by the percentage of time spent by engineers on on-call duty.
So, for on-call engineers, a runbook isn’t documentation in the literary sense. It’s a tool. What matters is whether it helps shorten the incident.
Why your docs lose at 3 AM
There are a few patterns that show up in almost every team that struggles with on-call docs. Let's take a look at some of them:
-
The docs aren’t where the alert is. The runbooks live on Confluence, the alert fires on PagerDuty, the dashboard is in Grafana, while Olivia is in her terminal. None was linked to the others. She is context-switching more often to get information; this is costing her thirty seconds per switch and a little more of her composure while she is frantically searching for a solution.
-
The runbook is a tutorial, not a checklist. It explains in deep details how the payments service works. It does not say if p99 > 2s, check queue depth first; if queue depth > 10k, scale workers; if workers are healthy, page the database team. The Diataxis framework nailed this distinction between tutorials, how-to-guides, references, and explanation. They are four different things, and runbooks are how-tos. You don’t need to start explaining in details.
-
The runbook is stale. It tells Olivia to restart payments-worker meanwhile, that service was renamed txn-processor seven months ago. She runs the command, gets service not found, and now she trusts nothing on that page.
-
Nobody owns it. The original author has left the company. The team that runs the service has never opened the doc to update it. There have been countless postmortem-generated action items to update runbooks that weren’t assigned to anyone or verified either.
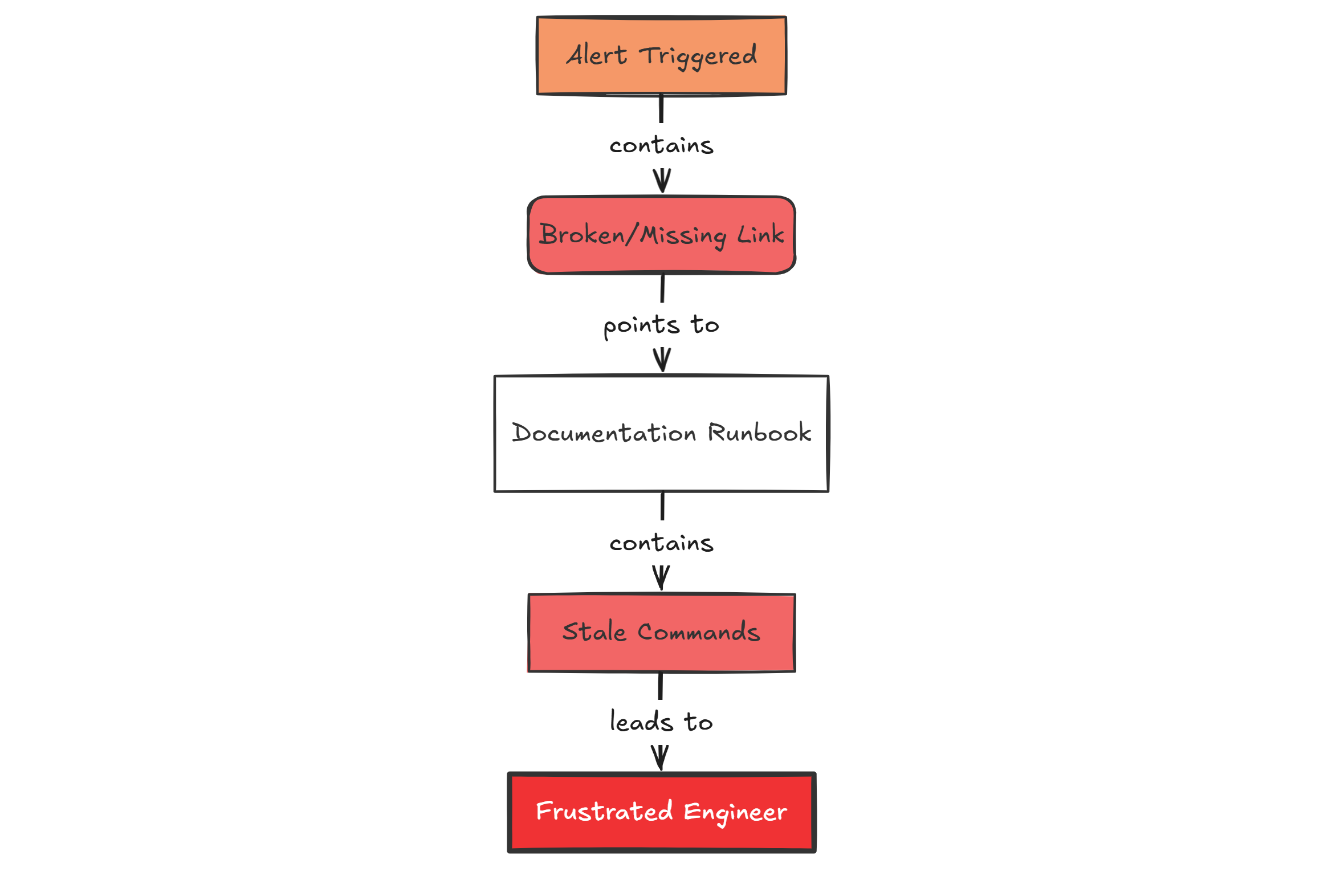
A flowchart showing a bad runbook chain reaction: the alert fires, the documentation link fails, the commands are outdated, and the engineer loses time during an incident.
What makes a runbook usable during incidents
For teams whose runbooks actually get read, share a few things in common.
-
They link the runbook from the alert itself. PagerDuty, Opsgenie, and Grafana Alerting all support adding runbook URLs in the alert payload. If your alert doesn’t include the link, it's like the runbook isn't available.
-
They start with action to take, not lots of context. The first thing on the page is what to do, how severe, what the symptoms look like, and commands you can copy to solve it. The explanations come much later, for those who want them after they’ve solved the problem.
-
They write for the worst version of the reader. The runbook works for someone who is half-asleep, new to the team, and has their adrenaline up. Not only for the senior engineer who wrote it.
-
They treat every incident as a doc bug. As Atlassian’s incident handbook puts it: "Every incident should be tracked and documented so you can identify trends and make comparisons over time."
-
They keep runbooks close to code. The Markdown is in the same repo as the code. The runbooks are reviewed in the same PR change that needs it. When docs live far from the code, they tend to rot. And that’s because those writing the code for the fix aren’t going to navigate to a separate wiki to update it.
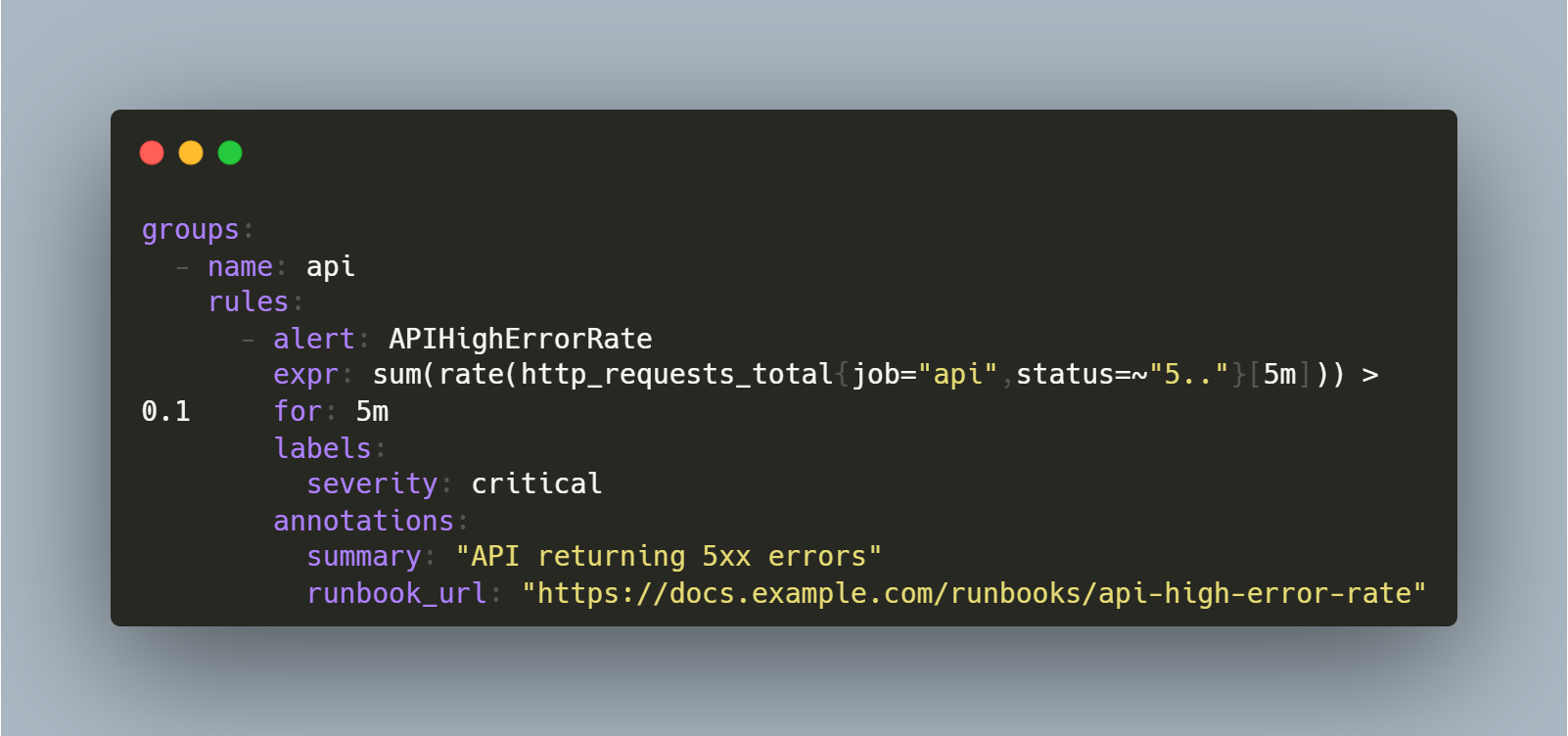
Runbook link included directly in the alert payload for quick access during incidents.
The uncomfortable part
If you’re a docs engineer and the on-call team keeps ignoring your work, it’s tempting to blame them for not searching, reading, or following the process. With a customer-facing outage happening, they definitely would want a solution fast.
The reader, just like Olivia you’re writing for, is exhausted, scared, and looking for one specific sentence that tells her what to do next to fix the problem. Make sure you write that sentence, put it at the top, link it from the alert, update it after every incident, and delete what is not needed.
The on-call engineer doesn’t read your docs, so make docs that don’t need to be read, but only used.